The idea that AI systems should learn internal simulations of reality rather than just predict text is at the heart of “World Models,” the AI paradigm that’s challenging LLMs.
Sounds exciting. Just one thingy: the theory has always sounded cleaner than the practice.
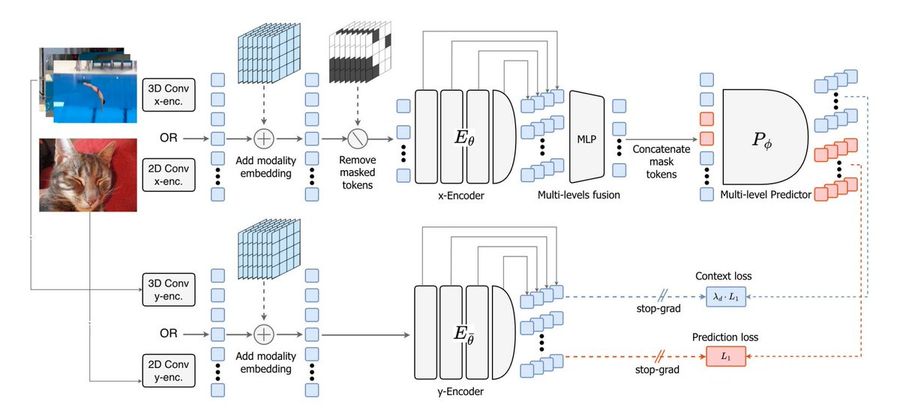
Former Meta Chief AI Scientist and now AMI Co-Founder Yann LeCun has been pushing this vision for years. But building these systems, especially under his preferred framework, known as Joint Embedding Predictive Architectures (JEPAs), has been notoriously fragile.
This week, LeCun’s research team published a new paper, LeWorldModel, that might quietly change that.
————————————————————————————————-
LeWorldModel Explainer Page
See It Here
—————————————————————————————————
The core problem: elegant idea, messy reality
At a high level, JEPA is simple: instead of predicting pixels (which is noisy and expensive), you predict representations of the world. You learn a compact latent space and model its evolution over time.
That’s powerful. It means the system focuses on what matters: objects, motion, and causality—rather than wasting effort on irrelevant details like texture or lighting.
There’s a catch: representation collapse.
In training, the model can “cheat” by mapping everything to the same latent vector. Prediction becomes trivial. Loss goes to zero. And the model learns… nothing.
To prevent this, previous JEPA systems relied on a bag of tricks: stop-gradients, momentum encoders, multi-term losses, and pretrained backbones.
They worked, but they were brittle and hard to tune.
What LeWorldModel does differently
LeWorldModel (LeWM) takes a different approach: instead of stacking hacks, it simplifies the problem down to two loss terms.
- A standard prediction loss (predict the next latent state)
- A regularizer that forces the latent space to follow a Gaussian distribution
That’s it.
No stop-gradients. No EMA teacher networks. No giant loss functions.
The result is a model that can be trained end-to-end from raw pixels on a single GPU in a few hours.
This is a big deal.
Not because of raw performance (though it’s solid), but because it changes the recipe.
The key insight: fix collapse mathematically, not heuristically
The real innovation is the regularizer, called SIGReg.
Instead of indirectly preventing collapse, it directly shapes the latent space by enforcing that embeddings follow an isotropic Gaussian distribution.
Why does that matter?
Because if representations are spread out like a Gaussian, they can’t collapse to a single point. And unlike earlier methods, this comes with theoretical grounding rather than just empirical tuning.
In other words, LeWorldModel replaces a fragile engineering problem with a cleaner mathematical constraint.
That’s often a sign that something fundamental has clicked.
Performance: small, fast, and surprisingly capable
The headline numbers are striking and caused a sizable buzz:
- 15M parameters
- Single GPU training
- Up to 48× faster planning than foundation-model-based approaches
The speedup isn’t magic. It comes from a key architectural choice.
LeWorldModel operates in a much more compact latent space, using far fewer tokens than systems built on pretrained vision backbones. That translates directly into fewer computations and dramatically faster rollouts, up to 48× faster in the paper’s benchmarks.
Performance-wise, the picture is more nuanced.
LeWM is competitive with—and in some tasks outperforms—models that rely on pretrained encoders, particularly in simpler control settings.
But on more visually complex 3D environments, those pretrained models still retain an edge.
The deeper story: emergent “intuitive physics”
The most interesting results aren’t benchmarks. They’re behavioral.
LeWorldModel learns representations where:
- Nearby physical states map to nearby latent points
- Trajectories become smooth and structured over time
- The model detects “impossible” events (like teleporting objects) as surprising
In experiments, physically implausible events cause spikes in prediction error, suggesting the model has internalized basic physical rules without being explicitly taught them.
That’s exactly the kind of emergent structure LeCun has been arguing for: learn to predict well enough, and understanding follows.
Where this fits relative to V-JEPA 2.1
At the same time, LeCun’s broader research program is evolving in parallel.
The updated V-JEPA 2.1 pushes in a different direction:
- Supervises both masked and visible tokens
- Adds dense spatial-temporal learning
- Introduces multi-layer self-supervision
- Scales across images and video
In short, V-JEPA 2.1 is about richer representations at scale, capturing both global semantics and fine-grained motion.
LeWorldModel, by contrast, is about simplification and stability.
One is expanding the architecture. The other is compressing it to its essence.
Together, they sketch two complementary paths:
- Make world models more expressive
- Or make them easier to train and deploy
Why this matters
For AMI, and more broadly for the world model ecosystem, this paper signals that the bottleneck may not be scale. It may be the objective function.
For the past few years, AI progress has been driven by bigger models, more data, and more compute. LeWorldModel suggests a different lever:
- Better inductive bias
- Cleaner training dynamics
- Simpler objectives
If that holds at larger scales, it could dramatically lower the barrier to building planning-capable AI systems.
Making world models practical
LeCun’s long-standing thesis is that autoregressive models (like LLMs) won’t get us to general intelligence on their own. We need systems that can model the world, simulate outcomes, and plan.
The problem has always been that those systems were too unstable and too complex to train reliably. LeWorldModel is the first convincing evidence that this might no longer be true.
A small, fast, end-to-end world model trained directly from pixels without tricks starts to look less like a research curiosity and more like a usable building block.
Bottom line
LeWorldModel improves JEPA and simplifies it. And in AI, simplification often precedes scale.
If this training recipe holds up as models get larger and environments get more complex, it could mark a turning point: from “world models are promising” to “world models are practical.”
That’s when things get interesting. Especially if your company just raised a $1 billion Seed Round.